SG.hu
Nem lehet egymással összehasonlítani az MI-modelleket, és ez baj

Melyik MI rendszer írja a legjobb számítógépes kódot, vagy generálja a legrealisztikusabb képet? Jelenleg nincs egyszerű módja annak, hogy megválaszoljuk ezeket a kérdéseket.
Van egy probléma az olyan vezető mesterséges intelligenciaeszközökkel, mint a ChatGPT, a Gemini és a Claude: nem igazán tudjuk, mennyire okosak. Ez azért van, mert az autókat, gyógyszereket vagy csecsemőtápszereket gyártó cégekkel ellentétben a mesterséges intelligenciával foglalkozó vállalatoknak nem kell tesztelniük a termékeiket, mielőtt a nyilvánosság elé tárják őket. Nem kell őket tanúsítani, és nincs olyan független csoport, amely szigorúan tesztelné ezeket. Ehelyett csak az MI vállalatok állításaira hagyatkozhatunk, amelyek gyakran olyan homályos kifejezéseket használnak, mint például "továbbfejlesztett képességek". Alig tudunk valamit arról, hogy modelljeik egyes verziói mennyiben különböznek egymástól, és bár vannak szabványos tesztek, amelyekkel mérik mennyire jók például matematikában vagy logikai gondolkodásban, sok szakértőnek kétségei vannak azzal kapcsolatban, hogy ezek a tesztek mennyire megbízhatóak.
Mindez kicsinyes panasznak hangozhat, de az MI-rendszerek megfelelő mérésének és értékelésének hiánya komoly probléma. Enélkül nem tudják az emberek, hogy melyik mire jó, vagy miben a legjobb. A ChatGPT vagy a Gemini ír jobb Python kódot? A DALL-E 3 vagy a Midjourney jobb emberek valósághű képének generálásában? A legtöbb technológiai vállalat nem tesz közzé felhasználói kézikönyveket vagy részletes kiadási jegyzeteket MI termékeihez. A modelleket pedig olyan gyakran frissítik, hogy egy chatbot, amely az egyik nap még nehezen boldogul egy feladattal, a következő nap már rejtélyes módon kiválóan teljesítheti azt.
A silány mérések biztonsági kockázatot is jelentenek. A modellek tesztelése nélkül nehéz tudni, hogy mely képességek fejlődnek a vártnál gyorsabban, vagy hogy mely termékek jelenthetnek valós veszélyt valamilyen szempontból. A Stanford Egyetem Emberközpontú Mesterséges Intelligencia Intézete által kiadott éves jelentésben a szerzők a mérések gyengeségét az egyik legnagyobb kihívásként írják le, amellyel az MI kutatók szembesülnek. "A szabványosított értékelés hiánya miatt rendkívül nagy kihívást jelent a különböző MI modellek korlátainak és kockázatainak szisztematikus összehasonlítása" - közölte a jelentés főszerkesztője, Nestor Maslej.
A mesterséges intelligencia mérésének legnépszerűbb módszere évekig az úgynevezett Turing-teszt volt. Az 1950-ben Alan Turing matematikus által javasolt gyakorlat azt vizsgálja, hogy egy számítógépes program képes-e becsapni egy embert úgy, hogy az összetéveszti-e a válaszait egy emberével. A mai mesterséges intelligencia rendszerek azonban kiválóan átmennek a Turing-teszten, és a kutatóknak új, nehezebb értékelési módszereket kellett kitalálniuk. Az egyik leggyakoribb teszt, amelyet manapság az MI modelleknek adnak - lényegében a chatbotok érettségije - a Massive Multitask Language Understanding (MMLU) nevű teszt.
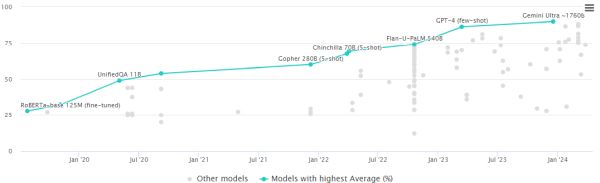
Az MMLU teszt szerint jelenleg a Google Gemini Ultra modellje a legjobb
A 2020-ban kiadott MMLU nagyjából 16 000 feleletválasztós kérdésből álló gyűjtemény, amely több tucat tudományos témát fed le az absztrakt algebrától kezdve a jogon át az orvostudományig. Egyfajta általános intelligenciateszt, minél több ilyen kérdésre válaszol helyesen egy chatbot, annál okosabb. Ez lett a dominanciáért versengő MI-cégek aranyszabványa. Amikor a Google az év elején kiadta legfejlettebb mesterséges intelligencia modelljét, a Gemini Ultra-t, azzal büszkélkedett, hogy 90 százalékos eredményt ért el az MMLU-n - ez a valaha mért legmagasabb pontszám.
Dan Hendrycks MI kutató a Berkeley-i Kaliforniai Egyetemen végzett egyetemi tanulmányai során részt vett az MMLU kifejlesztésében. Közlése szerint a teszt célja nem az, hogy dicsekedjen valaki az eredményeivel, és szerinte olyan gyorsan fejlődnek az Mi-rendszerek, hogy az MMLU "valószínűleg még egy-két évig működik", de hamarosan más, keményebb tesztekkel kell majd helyettesíteni. A mesterséges intelligencia rendszerek már túl okosak a mostani tesztekhez, és egyre nehezebb lesz újakat tervezni. "Az összes ilyen benchmark rossz, de néhány hasznos" - mondta. "Némelyikük egy meghatározott ideig szolgálhat némi hasznossággal, de egy bizonyos ponton olyan nagy nyomás nehezedik rá, hogy eléri a töréspontját."
Több tucatnyi más teszt létezik - olyan nevekkel, mint a TruthfulQA és a HellaSwag -, amelyek az MI teljesítmény más aspektusait hivatottak megragadni. De ahogyan az érettségi is csak egy részét ragadja meg egy diák intellektusának és képességeinek, úgy ezek a tesztek is csak egy szűk szeletét képesek mérni az MI rendszer teljesítményének. És egyiket sem úgy tervezték, hogy választ adjon a felhasználók szubjektívebb kérdéseire, mint például: Élvezetes-e ezzel a chatrobottal beszélgetni? A rutinszerű irodai munkára vagy a kreatív ötletelés automatizálására jobb? Mennyire szigorúak a biztonsági korlátok?
Magukkal a tesztekkel is lehetnek problémák. Az MMLU-hoz hasonló összehasonlító tesztek elvégzésének folyamata cégenként kissé eltérő, és a különböző modellek pontszámai nem feltétlenül hasonlíthatók össze közvetlenül. Létezik egy "adatszennyezés" néven ismert probléma, amikor az összehasonlító tesztek kérdései és válaszai bekerülnek egy mesterséges intelligencia modell képzési adatai közé, ami lényegében lehetővé teszi a modell számára a csalást. Ezeknek a modelleknek nincs független tesztelési vagy ellenőrzési folyamata, ami azt jelenti, hogy az MI-cégek lényegében a saját házi feladatukat osztályozzák.
Röviden, az MI-mérés egy zűrzavar - hanyag tesztek, almától a narancssárgáig terjedő összehasonlítások és öncélú hype összevisszasága, amely a felhasználókat, a szabályozó hatóságokat és magukat az MI-fejlesztőket is a sötétben tapogatózva hagyja. "A tudományosság látszata ellenére a legtöbb fejlesztő valójában a modelleket a megérzések vagy az ösztönök alapján ítéli meg" - mondta Nathan Benaich, az Air Street Capital befektetője. "Ez egyelőre még rendben lehet, de ahogy ezeknek a modelleknek egyre nagyobb lesz a hatalmuk és a társadalmi jelentőségük, ez már nem lesz elegendő."


Abraham Lincoln számítógépet használva ül asztala előtt - felül a DALL-E 3, alul a Midjourney v6 alkotása. Melyik a jobb?
A megoldás valószínűleg az állami és magánerőforrások kombinációja. A kormányoknak olyan robusztus tesztelési programokkal kell és lehet előállniuk, amelyek mind az MI modellek nyers képességeit, mind a biztonsági kockázatokat mérik, és olyan ösztöndíjakat és kutatási projekteket kell finanszírozniuk, amelyek célja új, magas színvonalú értékelések kidolgozása. Ez a folyamat már el is kezdődött: az MI-ről szóló tavalyi végrehajtási rendeletében a Fehér Ház több szövetségi ügynökséget, köztük a Nemzeti Szabványügyi és Technológiai Intézetet utasította, hogy hozzanak létre és felügyeljenek új módszereket az MI-rendszerek értékelésére.
Akadémiai körökben is tapasztalható némi előrelépés. Tavaly a Stanford kutatói új tesztet vezettek be a képgeneráló modellek számára, amely automatizált tesztek helyett emberi értékelőket használ annak megállapítására, hogy egy modell mennyire alkalmas. A Berkeley-i Kaliforniai Egyetem kutatóinak egy csoportja pedig nemrégiben indította el a Chatbot Arena nevű népszerű ranglistát, amely névtelen, véletlenszerűen kiválasztott mesterséges intelligencia modelleket állít egymással szembe, és arra kéri a felhasználókat, hogy szavazzanak a legjobb modellre.
Az MI-vállalatok azzal is segíthetnek, ha vállalják, hogy modelljeik tesztelése érdekében külső értékelőkkel és ellenőrökkel dolgoznak együtt, ha az új modelleket szélesebb körben elérhetővé teszik a kutatók számára, és ha modelljeik frissítésekor átláthatóbbak. Az Anthropic kutatói tavaly egy blogbejegyzésben azt írták, hogy "a hatékony MI kormányzás attól függ, hogy képesek vagyunk-e értelmesen értékelni a rendszereket". Igazuk van, hiszen a mesterséges intelligencia túl fontos technológia ahhoz, hogy a hangulatok alapján értékeljük. Amíg nem kapunk jobb módszereket ezen eszközök mérésére, nem fogjuk tudni, hogyan használjuk őket, vagy hogy a fejlődésüket ünnepelni vagy félni kell-e.
Van egy probléma az olyan vezető mesterséges intelligenciaeszközökkel, mint a ChatGPT, a Gemini és a Claude: nem igazán tudjuk, mennyire okosak. Ez azért van, mert az autókat, gyógyszereket vagy csecsemőtápszereket gyártó cégekkel ellentétben a mesterséges intelligenciával foglalkozó vállalatoknak nem kell tesztelniük a termékeiket, mielőtt a nyilvánosság elé tárják őket. Nem kell őket tanúsítani, és nincs olyan független csoport, amely szigorúan tesztelné ezeket. Ehelyett csak az MI vállalatok állításaira hagyatkozhatunk, amelyek gyakran olyan homályos kifejezéseket használnak, mint például "továbbfejlesztett képességek". Alig tudunk valamit arról, hogy modelljeik egyes verziói mennyiben különböznek egymástól, és bár vannak szabványos tesztek, amelyekkel mérik mennyire jók például matematikában vagy logikai gondolkodásban, sok szakértőnek kétségei vannak azzal kapcsolatban, hogy ezek a tesztek mennyire megbízhatóak.
Mindez kicsinyes panasznak hangozhat, de az MI-rendszerek megfelelő mérésének és értékelésének hiánya komoly probléma. Enélkül nem tudják az emberek, hogy melyik mire jó, vagy miben a legjobb. A ChatGPT vagy a Gemini ír jobb Python kódot? A DALL-E 3 vagy a Midjourney jobb emberek valósághű képének generálásában? A legtöbb technológiai vállalat nem tesz közzé felhasználói kézikönyveket vagy részletes kiadási jegyzeteket MI termékeihez. A modelleket pedig olyan gyakran frissítik, hogy egy chatbot, amely az egyik nap még nehezen boldogul egy feladattal, a következő nap már rejtélyes módon kiválóan teljesítheti azt.
A silány mérések biztonsági kockázatot is jelentenek. A modellek tesztelése nélkül nehéz tudni, hogy mely képességek fejlődnek a vártnál gyorsabban, vagy hogy mely termékek jelenthetnek valós veszélyt valamilyen szempontból. A Stanford Egyetem Emberközpontú Mesterséges Intelligencia Intézete által kiadott éves jelentésben a szerzők a mérések gyengeségét az egyik legnagyobb kihívásként írják le, amellyel az MI kutatók szembesülnek. "A szabványosított értékelés hiánya miatt rendkívül nagy kihívást jelent a különböző MI modellek korlátainak és kockázatainak szisztematikus összehasonlítása" - közölte a jelentés főszerkesztője, Nestor Maslej.
A mesterséges intelligencia mérésének legnépszerűbb módszere évekig az úgynevezett Turing-teszt volt. Az 1950-ben Alan Turing matematikus által javasolt gyakorlat azt vizsgálja, hogy egy számítógépes program képes-e becsapni egy embert úgy, hogy az összetéveszti-e a válaszait egy emberével. A mai mesterséges intelligencia rendszerek azonban kiválóan átmennek a Turing-teszten, és a kutatóknak új, nehezebb értékelési módszereket kellett kitalálniuk. Az egyik leggyakoribb teszt, amelyet manapság az MI modelleknek adnak - lényegében a chatbotok érettségije - a Massive Multitask Language Understanding (MMLU) nevű teszt.
Az MMLU teszt szerint jelenleg a Google Gemini Ultra modellje a legjobb
A 2020-ban kiadott MMLU nagyjából 16 000 feleletválasztós kérdésből álló gyűjtemény, amely több tucat tudományos témát fed le az absztrakt algebrától kezdve a jogon át az orvostudományig. Egyfajta általános intelligenciateszt, minél több ilyen kérdésre válaszol helyesen egy chatbot, annál okosabb. Ez lett a dominanciáért versengő MI-cégek aranyszabványa. Amikor a Google az év elején kiadta legfejlettebb mesterséges intelligencia modelljét, a Gemini Ultra-t, azzal büszkélkedett, hogy 90 százalékos eredményt ért el az MMLU-n - ez a valaha mért legmagasabb pontszám.
Dan Hendrycks MI kutató a Berkeley-i Kaliforniai Egyetemen végzett egyetemi tanulmányai során részt vett az MMLU kifejlesztésében. Közlése szerint a teszt célja nem az, hogy dicsekedjen valaki az eredményeivel, és szerinte olyan gyorsan fejlődnek az Mi-rendszerek, hogy az MMLU "valószínűleg még egy-két évig működik", de hamarosan más, keményebb tesztekkel kell majd helyettesíteni. A mesterséges intelligencia rendszerek már túl okosak a mostani tesztekhez, és egyre nehezebb lesz újakat tervezni. "Az összes ilyen benchmark rossz, de néhány hasznos" - mondta. "Némelyikük egy meghatározott ideig szolgálhat némi hasznossággal, de egy bizonyos ponton olyan nagy nyomás nehezedik rá, hogy eléri a töréspontját."
Több tucatnyi más teszt létezik - olyan nevekkel, mint a TruthfulQA és a HellaSwag -, amelyek az MI teljesítmény más aspektusait hivatottak megragadni. De ahogyan az érettségi is csak egy részét ragadja meg egy diák intellektusának és képességeinek, úgy ezek a tesztek is csak egy szűk szeletét képesek mérni az MI rendszer teljesítményének. És egyiket sem úgy tervezték, hogy választ adjon a felhasználók szubjektívebb kérdéseire, mint például: Élvezetes-e ezzel a chatrobottal beszélgetni? A rutinszerű irodai munkára vagy a kreatív ötletelés automatizálására jobb? Mennyire szigorúak a biztonsági korlátok?
Magukkal a tesztekkel is lehetnek problémák. Az MMLU-hoz hasonló összehasonlító tesztek elvégzésének folyamata cégenként kissé eltérő, és a különböző modellek pontszámai nem feltétlenül hasonlíthatók össze közvetlenül. Létezik egy "adatszennyezés" néven ismert probléma, amikor az összehasonlító tesztek kérdései és válaszai bekerülnek egy mesterséges intelligencia modell képzési adatai közé, ami lényegében lehetővé teszi a modell számára a csalást. Ezeknek a modelleknek nincs független tesztelési vagy ellenőrzési folyamata, ami azt jelenti, hogy az MI-cégek lényegében a saját házi feladatukat osztályozzák.
Röviden, az MI-mérés egy zűrzavar - hanyag tesztek, almától a narancssárgáig terjedő összehasonlítások és öncélú hype összevisszasága, amely a felhasználókat, a szabályozó hatóságokat és magukat az MI-fejlesztőket is a sötétben tapogatózva hagyja. "A tudományosság látszata ellenére a legtöbb fejlesztő valójában a modelleket a megérzések vagy az ösztönök alapján ítéli meg" - mondta Nathan Benaich, az Air Street Capital befektetője. "Ez egyelőre még rendben lehet, de ahogy ezeknek a modelleknek egyre nagyobb lesz a hatalmuk és a társadalmi jelentőségük, ez már nem lesz elegendő."
Abraham Lincoln számítógépet használva ül asztala előtt - felül a DALL-E 3, alul a Midjourney v6 alkotása. Melyik a jobb?
A megoldás valószínűleg az állami és magánerőforrások kombinációja. A kormányoknak olyan robusztus tesztelési programokkal kell és lehet előállniuk, amelyek mind az MI modellek nyers képességeit, mind a biztonsági kockázatokat mérik, és olyan ösztöndíjakat és kutatási projekteket kell finanszírozniuk, amelyek célja új, magas színvonalú értékelések kidolgozása. Ez a folyamat már el is kezdődött: az MI-ről szóló tavalyi végrehajtási rendeletében a Fehér Ház több szövetségi ügynökséget, köztük a Nemzeti Szabványügyi és Technológiai Intézetet utasította, hogy hozzanak létre és felügyeljenek új módszereket az MI-rendszerek értékelésére.
Akadémiai körökben is tapasztalható némi előrelépés. Tavaly a Stanford kutatói új tesztet vezettek be a képgeneráló modellek számára, amely automatizált tesztek helyett emberi értékelőket használ annak megállapítására, hogy egy modell mennyire alkalmas. A Berkeley-i Kaliforniai Egyetem kutatóinak egy csoportja pedig nemrégiben indította el a Chatbot Arena nevű népszerű ranglistát, amely névtelen, véletlenszerűen kiválasztott mesterséges intelligencia modelleket állít egymással szembe, és arra kéri a felhasználókat, hogy szavazzanak a legjobb modellre.
Az MI-vállalatok azzal is segíthetnek, ha vállalják, hogy modelljeik tesztelése érdekében külső értékelőkkel és ellenőrökkel dolgoznak együtt, ha az új modelleket szélesebb körben elérhetővé teszik a kutatók számára, és ha modelljeik frissítésekor átláthatóbbak. Az Anthropic kutatói tavaly egy blogbejegyzésben azt írták, hogy "a hatékony MI kormányzás attól függ, hogy képesek vagyunk-e értelmesen értékelni a rendszereket". Igazuk van, hiszen a mesterséges intelligencia túl fontos technológia ahhoz, hogy a hangulatok alapján értékeljük. Amíg nem kapunk jobb módszereket ezen eszközök mérésére, nem fogjuk tudni, hogyan használjuk őket, vagy hogy a fejlődésüket ünnepelni vagy félni kell-e.